Since its first release back in year 2007 with compute capability 1.0, CUDA has three more architectural releases and eight more compute capabilities which marks the fact that it’s an ever evolving architecture. Although CUDA is forward compatible but every new release comes with its own new features worth using and an increased thread/memory support. As a rule of thumb every new architecture runs the CUDA code faster than previous generation given both cards have same number of cores.
The comparison below gives a list of feature/functionality support between compute capabilities of NVIDIA’s CUDA enabled devices. Note that atomic operations weren’t supported in the first release and since they are so important, NVIDIA now practically compares architectures from 1.1 and later.
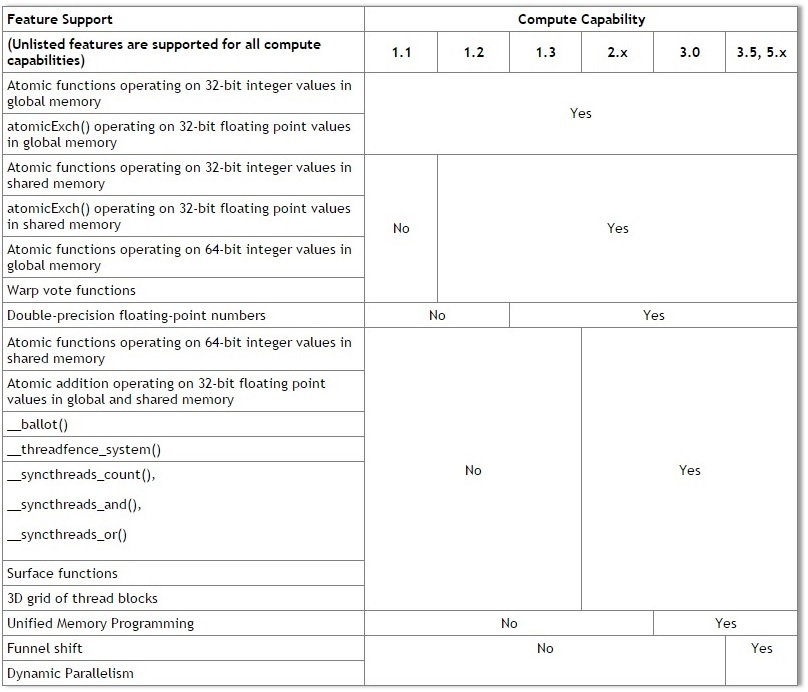
image courtesy: CUDA Programming Guide (v6.5)
Double Precision Support (1.3 and above)
Compute Capability 1.3 of Tesla architecture was a major release for the scientific community. Algorithms that required greater precision, could then be ported to CUDA to take advantage of parallelism without compromising on results which was not possible earlier. This was the point when scientific community started adopting CUDA in masses.
Fermi (2.x)
Fermi having compute capability of 2.0 has several differences from previous architectures. In addition to increasing the number of threads per blocks and packing 512 cores in a single chip, Fermi can also run multiple Kernels simultaneously. Shared memory has also been increased from 16 KB to 48 KB and most importantly the number of streaming processors in one SM have been increased to 32.
Fermi also added support for 3D grid of thread block to visualize voxels and port 3-Dimensional problems more naturally.
Kepler (3.0 and 3.5)
NVIDIA’s Kepler architecture is built on the foundation of NVIDIA’s Fermi GPU architecture first established in 2010. Fermi presented a completely new parallel geometry pipeline optimized for tessellation and displacement mapping. Kepler continues to provide the best tessellation performance and combines this with new features specifically designed to deliver a smoother, richer and faster gaming experience. The core improvements in Kepler over Fermi are:
- More CUDA cores, up from 512 to 1536
- GPU Boost for automatic overclocking
- Refined instruction pipeline
- Adaptive Vsync
- Low power consumption
The comparison below is more technical for those who love to think at the hardware level and experiment with threads, blocks and memory to get the best performance. In general, the limits in this chart either increased or remain constant as we move towards newer generation.
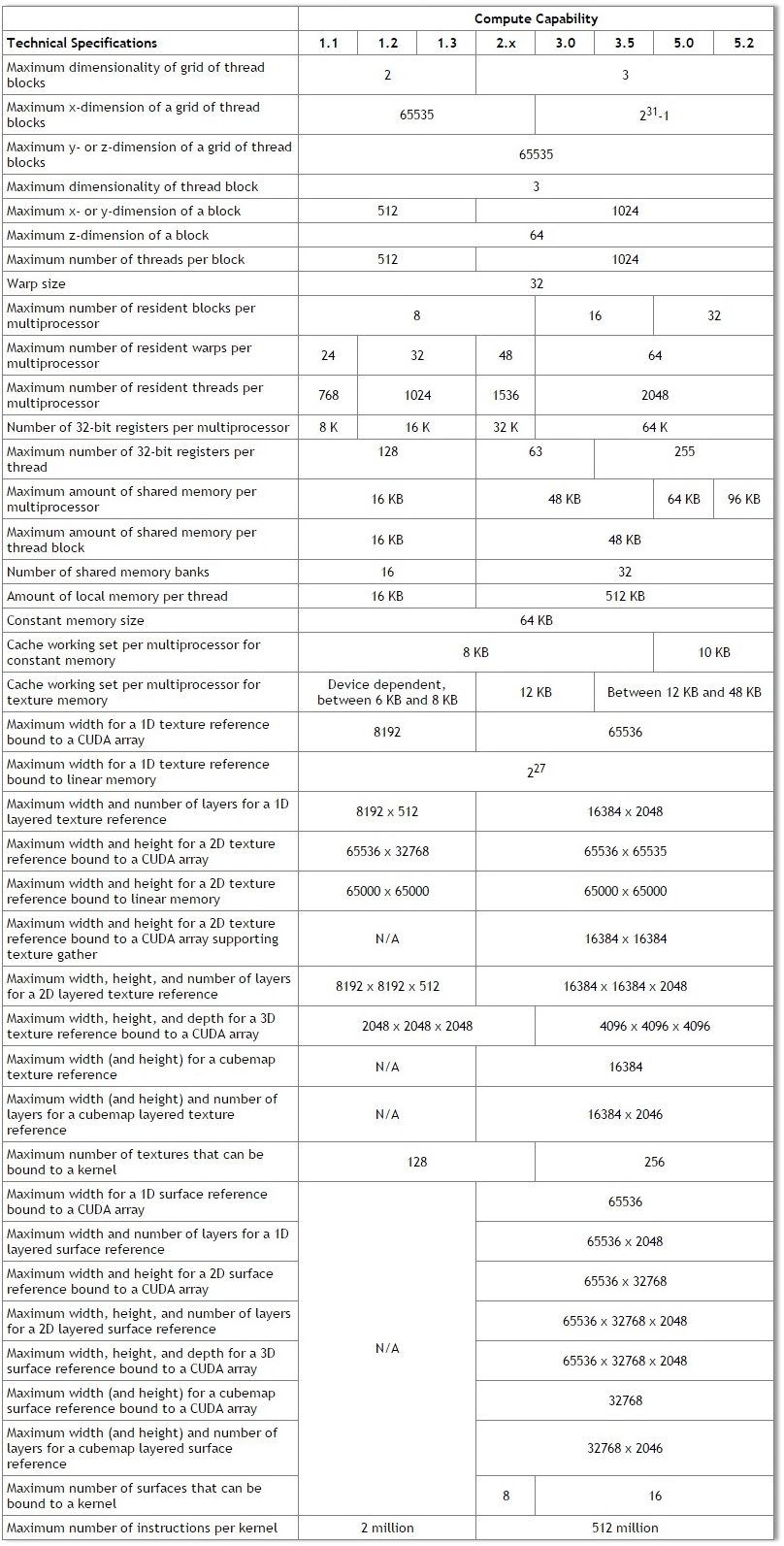
image courtesy: CUDA Programming Guide (v6.5)
Note: This is a live page and gets updated with every new CUDA release.
CUVIlib - CUDA Vision & Imaging Library - is a simple to use, GPU accelerated computer vision SDK. The library is available for download for free for personal unlimited use. For more information, visit our website at cuvilib.com.